【中編】音声合成ワークフローの構築
このモジュールで学ぶこと
- 動画ファイルをGoogle Driveからダウンロードする方法
- Fish Audio APIでナレーション音声を生成する方法
- ffmpegで動画と音声を合成する方法
- n8nでファイルをディスクに保存・読み込みする方法
- 処理済み動画をGoogle Driveにアップロードする方法
学習目標
このモジュールを終えると、以下のことができるようになります:
- HTTP RequestノードでFish Audio APIを呼び出せる
- Execute Commandノードでffmpegを実行できる
- Read/Write Files from Diskノードでファイル操作ができる
- 複数ノード間でバイナリデータを受け渡しできる
- 元ファイルのアーカイブと新ファイルのアップロードを自動化できる
目次
- セクション1: 動画ファイルのダウンロード
- セクション2: Fish Audio APIで音声生成
- セクション3: ファイルをディスクに保存
- セクション4: ffmpegで動画と音声を合成
- セクション5: 合成済み動画の読み込み
- セクション6: 元動画のアーカイブと新動画のアップロード
- トラブルシューティング
- まとめ
- よくある質問
事前準備
必要なもの
- Module 02(前編)完了済み(ワークフローが「If Video Exists」まで作成済み)
- ffmpegがn8nコンテナにインストール済み(Module 01参照)
- Fish Audio API Credentialが設定済み(Module 01参照)
前編からの引き継ぎ
前編で以下のノードまで作成済みです:
- Manual Trigger → Get canva_A → Filter Pending → Set Folder Names
- → Search Category Folder → Search Archive Folder → If Archive Exists
- → Create Archive Folder → Prepare Loop Data → Loop Over Items
- → Search Video File → If Video Exists
セクション1: 動画ファイルのダウンロード
Step 1: Download fileノードを追加
If Video Existsの「true」出力から動画をダウンロードします。
- If Video Existsの「true」出力から「+」をクリック
- 「Google Drive」を検索して追加
- ノード名を「Download file」に変更
- 設定:
| 設定項目 | 値 |
|---|---|
| Action | Download file |
| File | By ID |
| File ID | {{ $('Search Video File').item.json.id }}(Expressionモード) |
- 「Test Workflow」でワークフロー全体を実行してテスト
Download fileの実行結果:
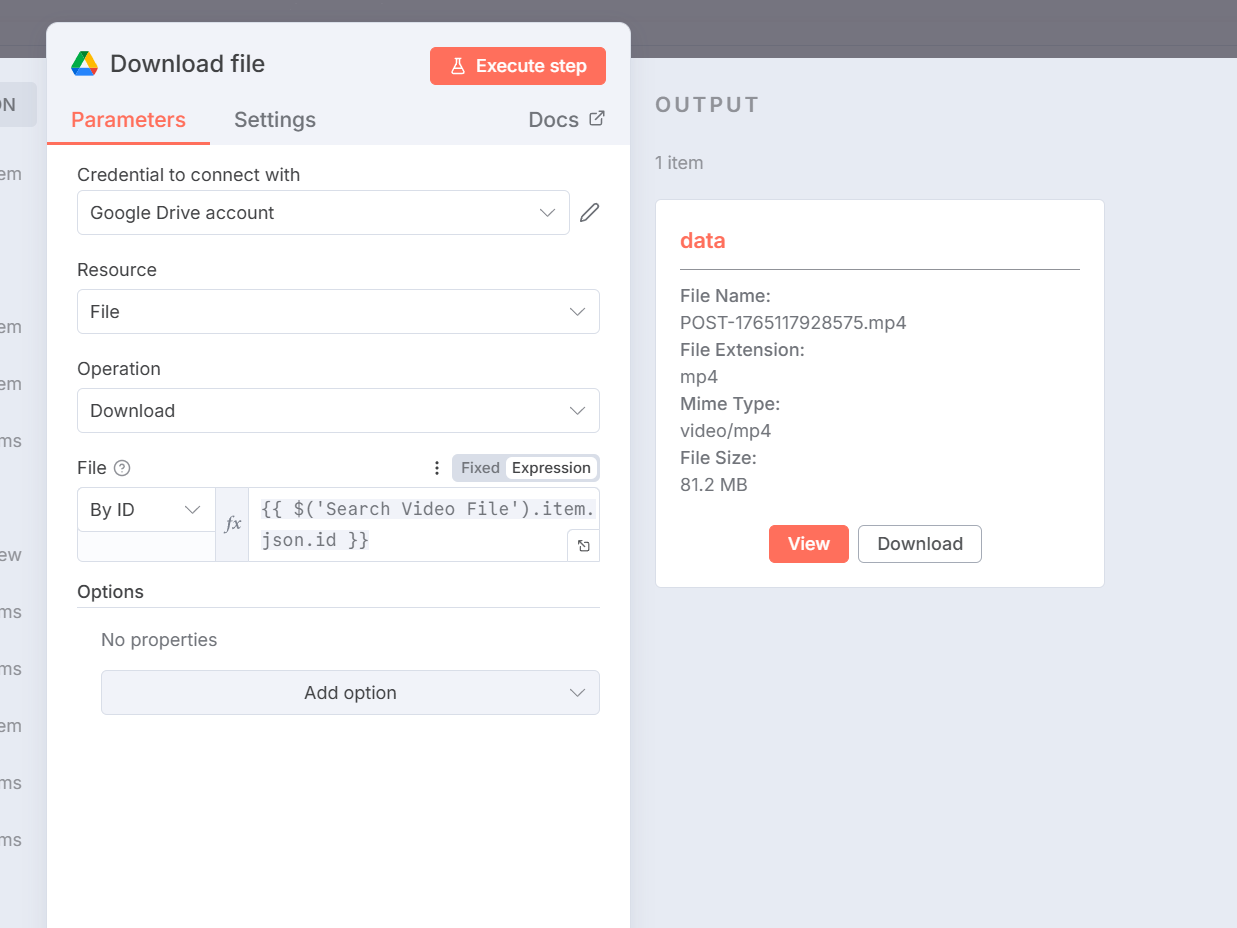
動画ファイル(約80MB)がダウンロードされればOKです。
チェックポイント
- Download fileで動画がダウンロードできた
- 出力にバイナリデータ(data)が含まれている
セクション2: Fish Audio APIで音声生成
Step 2: Generate Audio 1ノードを追加
前半30秒分のナレーション(narration_1)を音声に変換します。
- Download fileから「+」をクリック
- 「HTTP Request」を検索して追加
- ノード名を「Generate Audio 1」に変更
- 設定:
| 設定項目 | 値 |
|---|---|
| Method | POST |
| URL | https://api.fish.audio/v1/tts |
| Authentication | Generic Credential Type |
| Generic Auth Type | Header Auth |
| Header Auth | Fish Audio API |
- Send Body: ON
- Body Content Type: JSON
- Specify Body: Using JSON
- JSON:
{
"text": "{{ $('Loop Over Items').item.json.narration_1 }}",
"reference_id": "YOUR_VOICE_ID"
}
注意: YOUR_VOICE_IDはModule 01で取得したFish AudioのVoice IDに置き換えてください。
Step 3: Wait 5sノードを追加
API呼び出しの間隔を空けるためにWaitノードを追加します。
- Generate Audio 1から「+」をクリック
- 「Wait」を検索して追加
- ノード名を「Wait 5s」に変更
- 設定:デフォルト(5秒待機)のままでOK
Step 4: Generate Audio 2ノードを追加
後半30秒分のナレーション(narration_2)を音声に変換します。
- Wait 5sから「+」をクリック
- 「HTTP Request」を検索して追加
- ノード名を「Generate Audio 2」に変更
- 設定:
| 設定項目 | 値 |
|---|---|
| Method | POST |
| URL | https://api.fish.audio/v1/tts |
| Authentication | Generic Credential Type |
| Generic Auth Type | Header Auth |
| Header Auth | Fish Audio API |
- Send Body: ON
- Body Content Type: JSON
- Specify Body: Using JSON
- JSON:
{
"text": "{{ $('Loop Over Items').item.json.narration_2 }}",
"reference_id": "YOUR_VOICE_ID"
}
Generate Audio 1の実行結果:
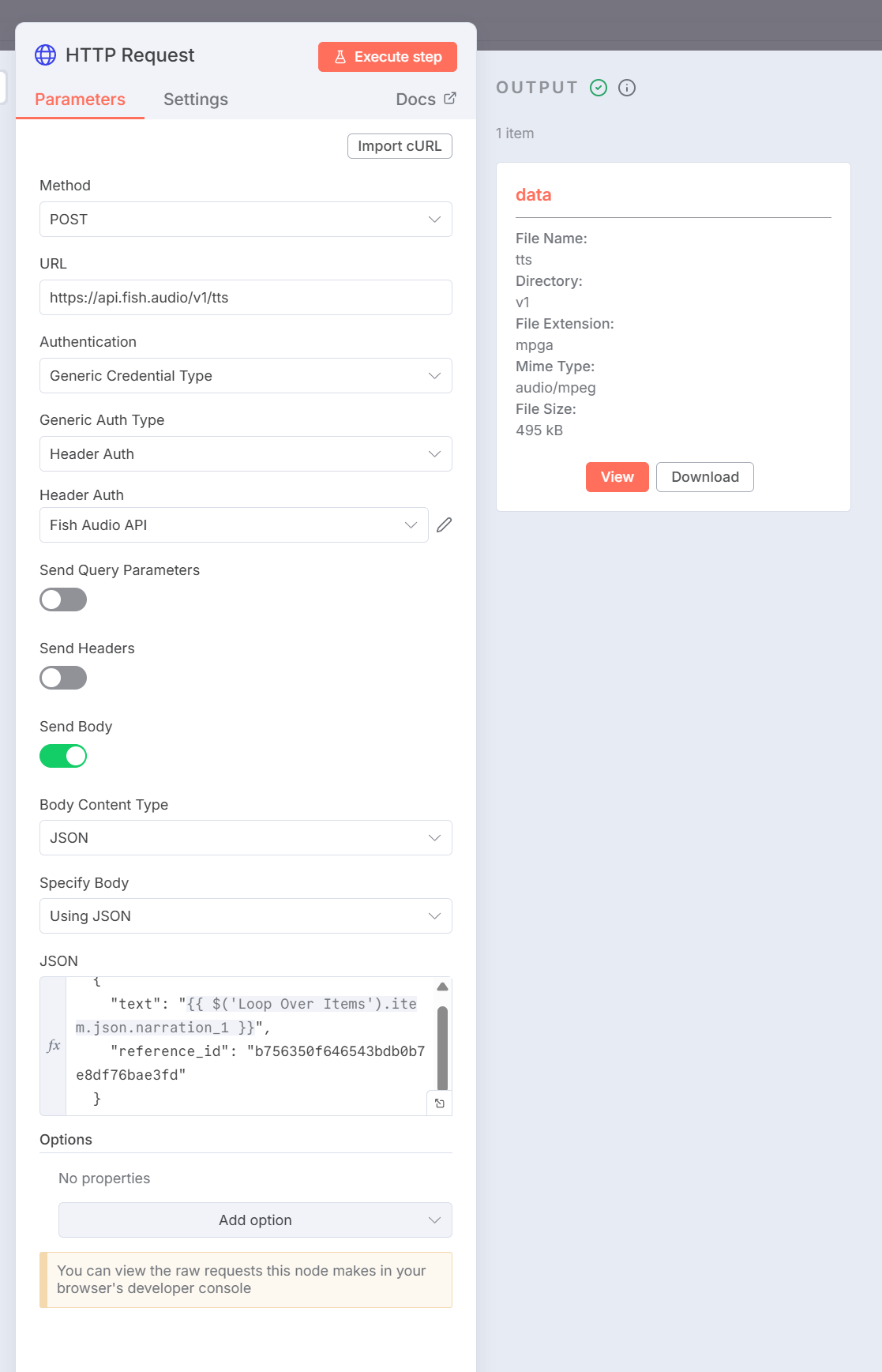
Generate Audio 2の実行結果:
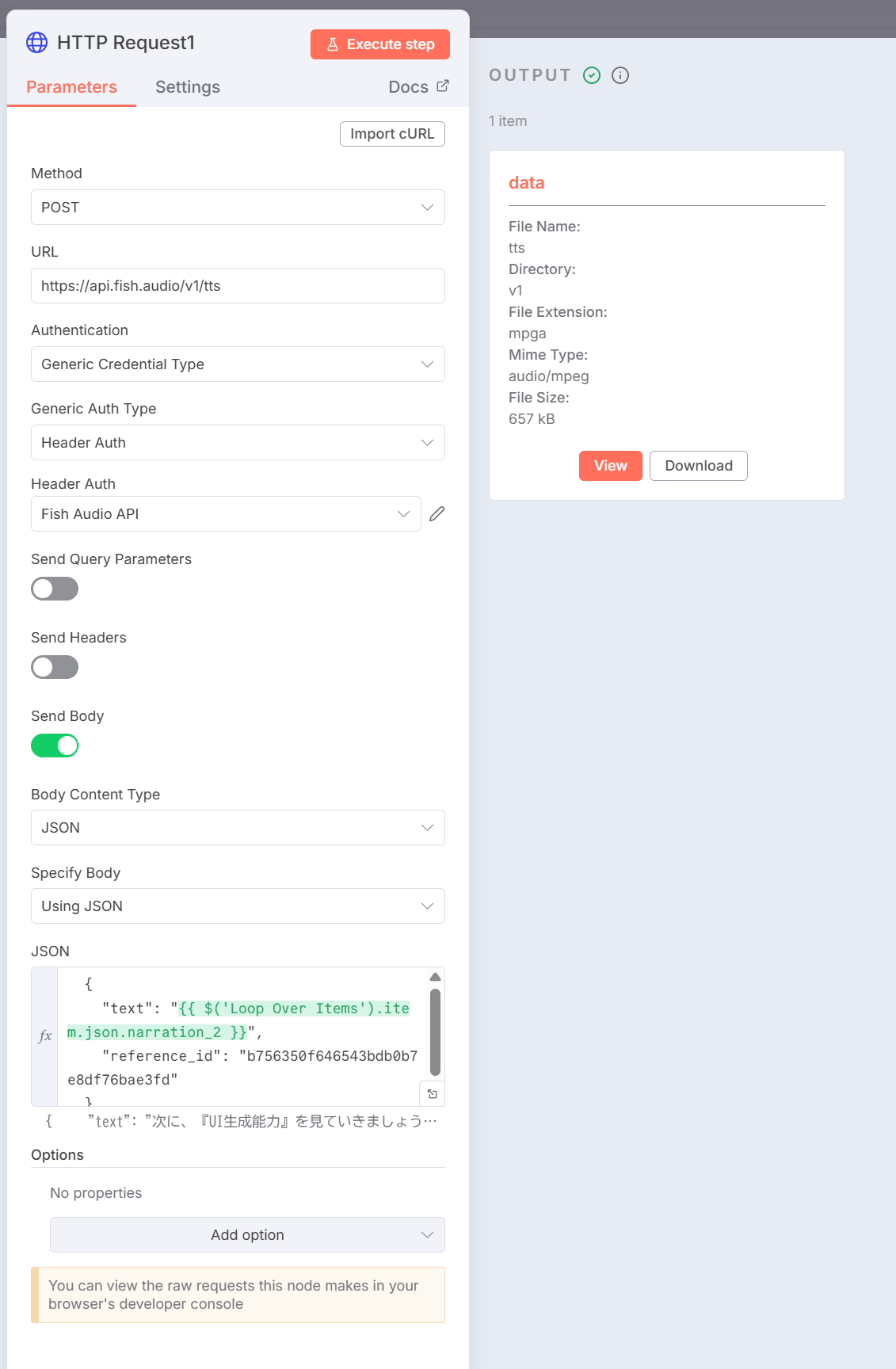
チェックポイント
- Generate Audio 1で音声ファイル(audio/mpeg)が生成された
- Generate Audio 2で音声ファイル(audio/mpeg)が生成された
セクション3: ファイルをディスクに保存
ffmpegはディスク上のファイルを処理するため、バイナリデータをファイルとして保存する必要があります。
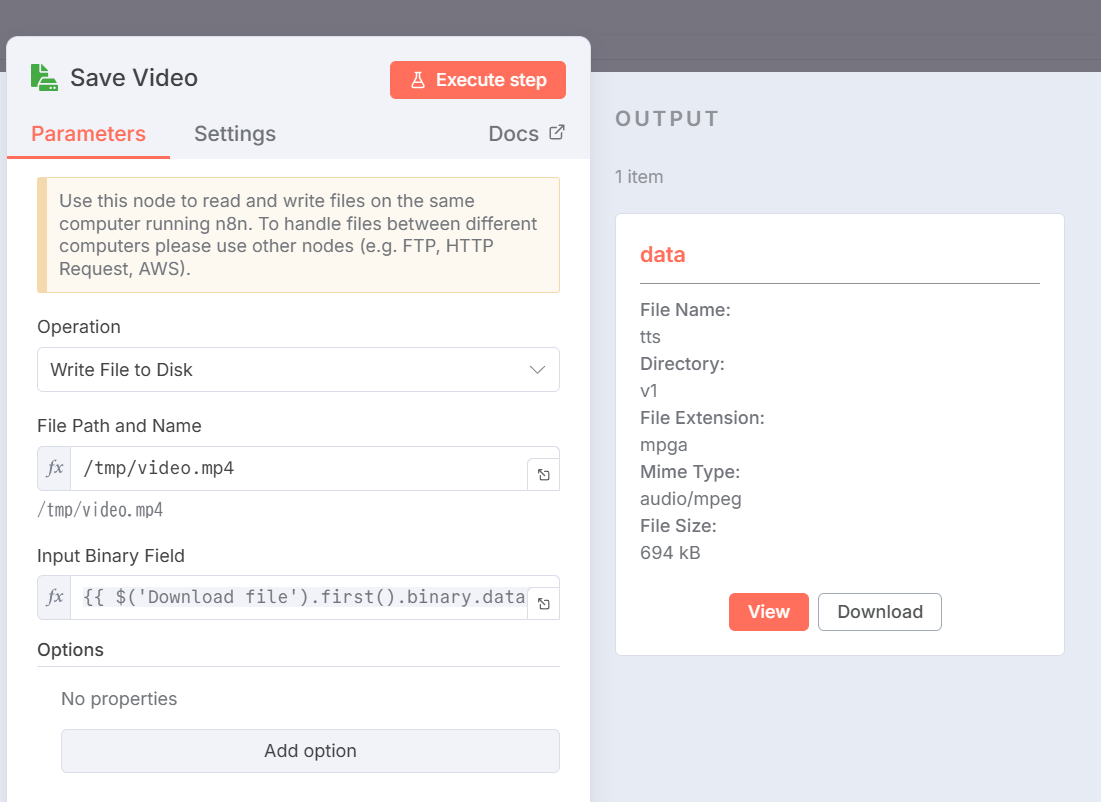
Step 5: Save Videoノードを追加
ダウンロードした動画をディスクに保存します。
- Generate Audio 2から「+」をクリック
- 「Read/Write Files from Disk」を検索して追加
- ノード名を「Save Video」に変更
- 設定:
| 設定項目 | 値 |
|---|---|
| Operation | Write File to Disk |
| File Path and Name | /tmp/video.mp4 |
| Input Binary Field | {{ $('Download file').first().binary.data }}(Expressionモード) |
重要: Input Binary Fieldは前のノード(Generate Audio 2)のバイナリデータではなく、Download fileのバイナリデータを参照します。これは式で別のノードのデータを明示的に指定しています。
Save Videoの設定画面:
Step 6: Save Audio 1ノードを追加
前半の音声をディスクに保存します。
- Save Videoから「+」をクリック
- 「Read/Write Files from Disk」を検索して追加
- ノード名を「Save Audio 1」に変更
- 設定:
| 設定項目 | 値 |
|---|---|
| Operation | Write File to Disk |
| File Path and Name | /tmp/audio1.mp3 |
| Input Binary Field | {{ $('Generate Audio 1').first().binary.data }}(Expressionモード) |
Step 7: Save Audio 2ノードを追加
後半の音声をディスクに保存します。
- Save Audio 1から「+」をクリック
- 「Read/Write Files from Disk」を検索して追加
- ノード名を「Save Audio 2」に変更
- 設定:
| 設定項目 | 値 |
|---|---|
| Operation | Write File to Disk |
| File Path and Name | /tmp/audio2.mp3 |
| Input Binary Field | {{ $('Generate Audio 2').first().binary.data }}(Expressionモード) |
チェックポイント
- Save Videoでファイルが保存された
- Save Audio 1でファイルが保存された
- Save Audio 2でファイルが保存された
セクション4: ffmpegで動画と音声を合成
Step 8: Execute Commandノードを追加
ffmpegで動画と2つの音声を合成します。
- Save Audio 2から「+」をクリック
- 「Execute Command」を検索して追加
- ノード名を「Execute Command」のままでOK
- 設定:
| 設定項目 | 値 |
|---|---|
| Execute Once | ON |
| Command | 下記参照 |
Command:
ffmpeg -y -i /tmp/video.mp4 -i /tmp/audio1.mp3 -i /tmp/audio2.mp3 -filter_complex '[1:a]adelay=0|0[a1];[2:a]adelay=30000|30000[a2];[a1][a2]amix=inputs=2[aout]' -map 0:v -map '[aout]' -c:v copy -c:a aac /tmp/output.mp4
コマンドの解説:
| オプション | 説明 |
|---|---|
| -y | 出力ファイルを上書き |
| -i /tmp/video.mp4 | 入力1: 動画 |
| -i /tmp/audio1.mp3 | 入力2: 前半音声 |
| -i /tmp/audio2.mp3 | 入力3: 後半音声 |
| -filter_complex | 複数入力を処理 |
| adelay=0|0 | 前半音声を0秒から開始 |
| adelay=30000|30000 | 後半音声を30秒から開始 |
| amix=inputs=2 | 2つの音声をミックス |
| -map 0:v | 動画トラックを使用 |
| -map '[aout]' | 合成した音声を使用 |
| -c:v copy | 動画は再エンコードなし |
| -c:a aac | 音声はAACエンコード |
- 「Test Workflow」でワークフロー全体を実行してテスト
Execute Commandの実行結果:

exitCode: 0 が出力されれば成功です。
チェックポイント
- Execute Commandでexitcode: 0が出力された
- /tmp/output.mp4が作成された
セクション5: 合成済み動画の読み込み
Step 9: Read Outputノードを追加
ffmpegで作成した合成済み動画を読み込みます。
- Execute Commandから「+」をクリック
- 「Read/Write Files from Disk」を検索して追加
- ノード名を「Read Output」に変更
- 設定:
| 設定項目 | 値 |
|---|---|
| Operation | Read File(s) From Disk |
| File(s) Selector | /tmp/output.mp4 |
- 「Test Workflow」でワークフロー全体を実行してテスト
Read Outputの実行結果:
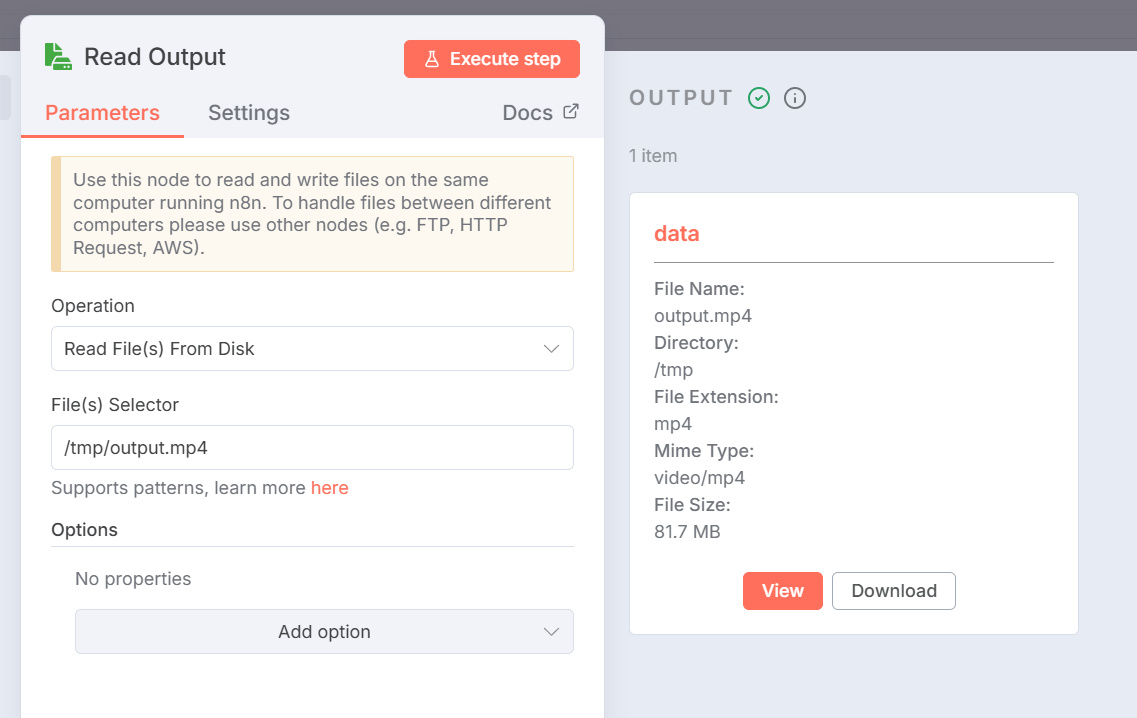
出力に video/mp4 のバイナリデータが表示されればOKです。
チェックポイント
- Read Outputで動画ファイルが読み込まれた
- Mime Type: video/mp4が表示されている
セクション6: 元動画のアーカイブと新動画のアップロード
Step 10: Move Original to Archiveノードを追加
元の動画をアーカイブフォルダに移動します。
- Read Outputから「+」をクリック
- 「Google Drive」を検索して追加
- ノード名を「Move Original to Archive」に変更
- 設定:
| 設定項目 | 値 |
|---|---|
| Action | Move file |
| File | By ID |
| File ID | {{ $('Search Video File').first().json.id }}(Expressionモード) |
| Parent Drive | My Drive |
| Parent Folder | By ID |
| Folder ID | {{ $('Search Archive Folder').first().json.id }}(Expressionモード) |
Move Original to Archiveの実行結果:
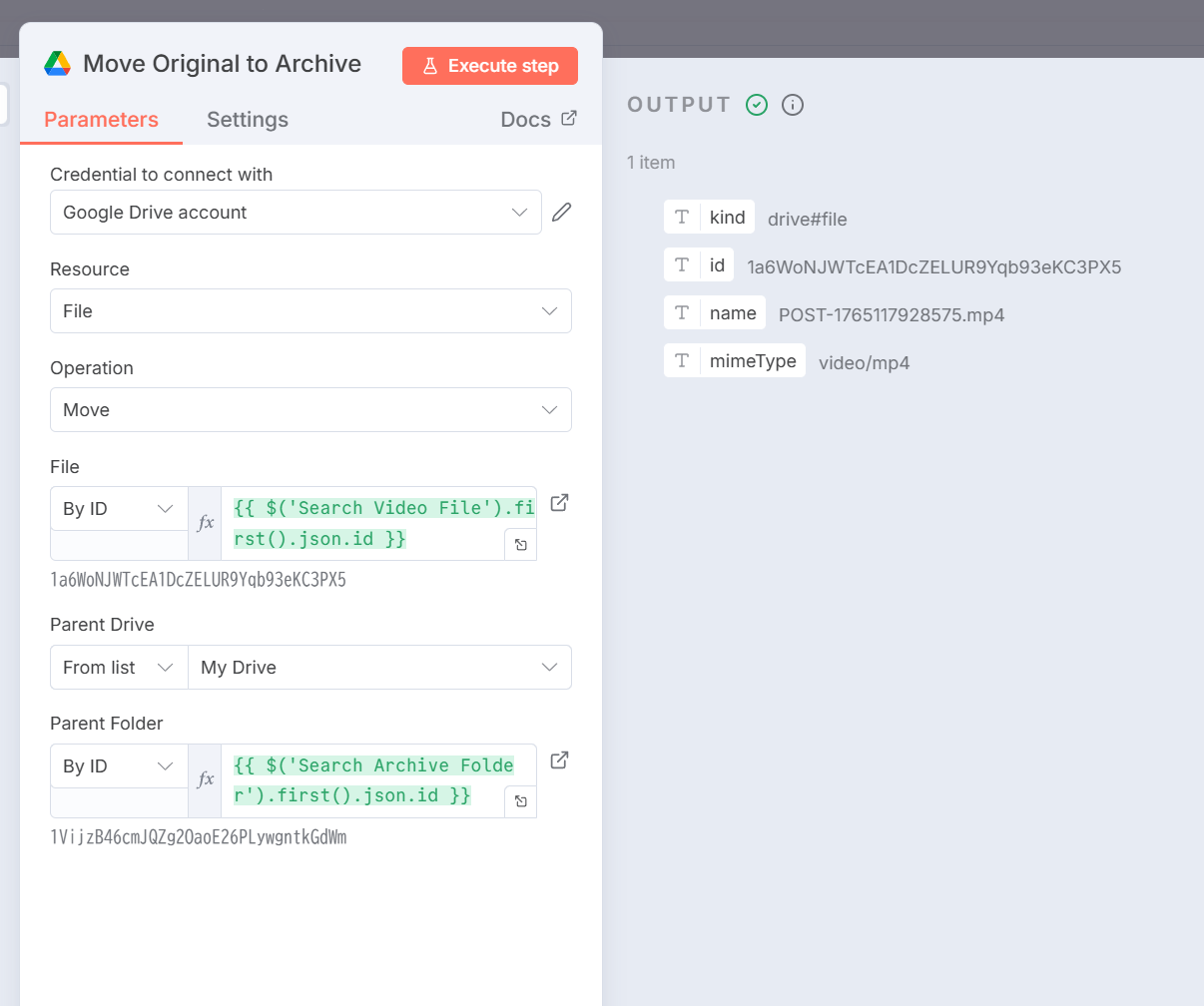
Step 11: Wait 5s1ノードを追加
アップロード前に少し待機します。
- Read Outputから「+」をクリック(Move Original to Archiveと並列で接続)
- 「Wait」を検索して追加
- ノード名を「Wait 5s1」に変更
- 設定:デフォルト(5秒待機)のままでOK
重要: Read Outputから2つのノード(Move Original to ArchiveとWait 5s1)に並列で接続します。これにより、元動画の移動と新動画のアップロードを両方実行できます。
Step 12: Upload New Videoノードを追加
音声合成済みの動画を元のフォルダにアップロードします。
- Wait 5s1から「+」をクリック
- 「Google Drive」を検索して追加
- ノード名を「Upload New Video」に変更
- 設定:
| 設定項目 | 値 |
|---|---|
| Action | Upload file |
| Input Data Field Name | data |
| File Name | {{ $('Search Video File').first().json.name }}(Expressionモード) |
| Parent Drive | My Drive |
| Parent Folder | By ID |
| Folder ID | {{ $('Loop Over Items').item.json.category_folder_id }}(Expressionモード) |
Upload New Videoの実行結果:
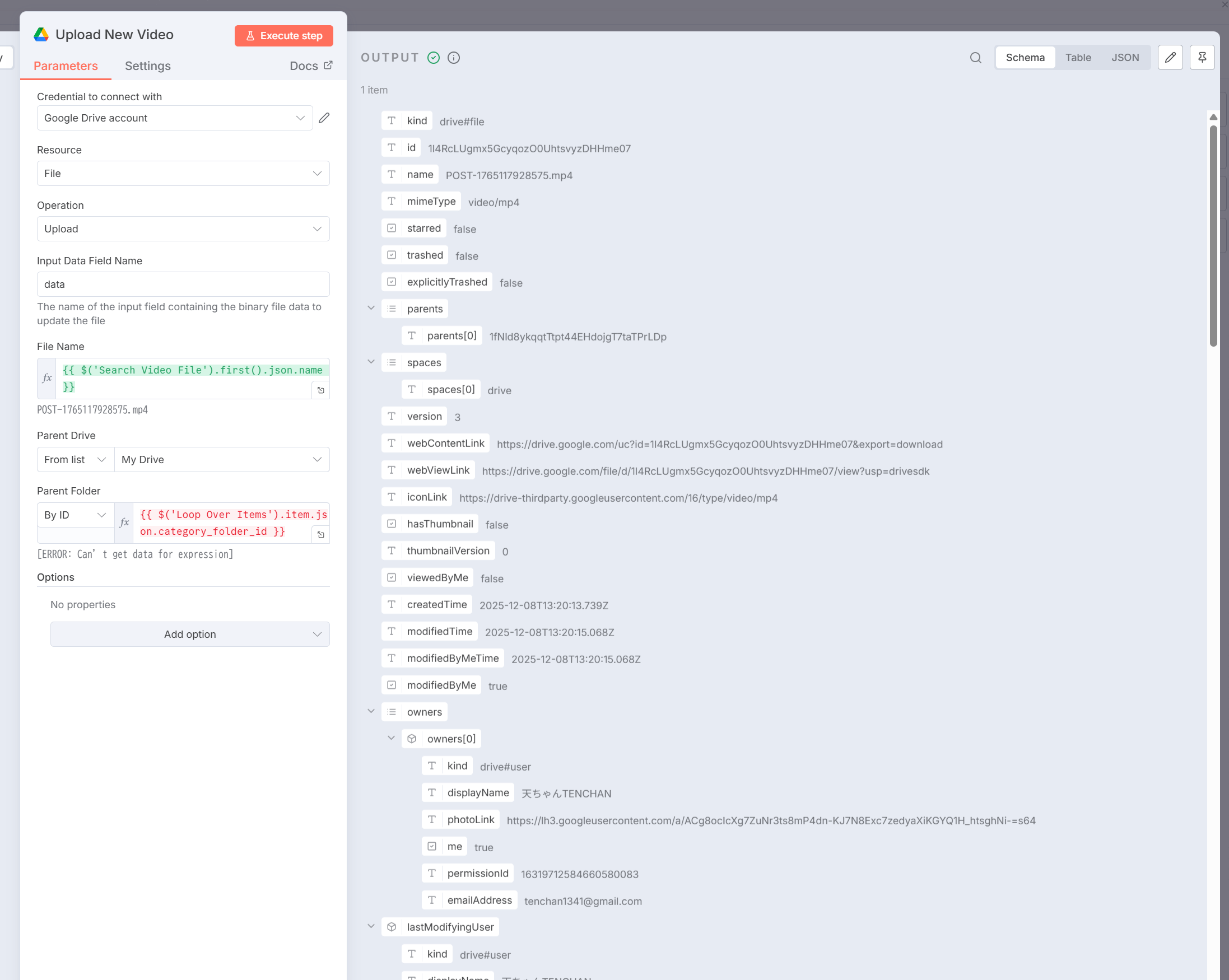
完成したワークフロー
すべてのノードが正常に実行され、ワークフローが完成しました:

チェックポイント
- Move Original to Archiveで元動画がアーカイブフォルダに移動した
- Upload New Videoで新動画が元のフォルダにアップロードされた
- Google Driveで確認:元フォルダに同名の新動画、アーカイブフォルダに元動画
トラブルシューティング
Fish Audio APIで「400 Bad Request」エラーが出る
症状: Generate Audio 1/2でBad Requestエラーが発生する
原因: HTTPメソッドがGETになっている、またはJSONボディが正しく設定されていない
解決方法:
- MethodがPOSTになっているか確認
- Specify Bodyが「Using JSON」になっているか確認
- JSONの構文が正しいか確認(波括弧の対応など)
ffmpegで「Missing argument for option 'filter_complex'」エラーが出る
症状: Execute Commandでffmpegがエラーになる
原因: filter_complexの引用符がシェルで正しく解釈されていない
解決方法: filter_complexの引数をシングルクォートで囲む(本講座のコマンドで対応済み)
Upload New Videoで「binary file 'data' not found」エラーが出る
症状: アップロード時にバイナリデータが見つからないエラー
原因: 前のノード(Move Original to Archive)がバイナリデータを渡さない
解決方法: Read Outputから直接Upload New Videoに接続する(Wait 5s1を経由)。Move Original to Archiveとは並列で接続する。
ファイルが大きすぎてエラーになる
症状: 「PayloadTooLargeError: request entity too large」エラー
原因: 動画ファイル(80MB以上)がn8nのメモリ制限を超えている
解決方法: ファイルをディスクに保存してからffmpegで処理する(本講座の方式で対応済み)
まとめ
このモジュールで学んだこと
- HTTP RequestノードでFish Audio APIを呼び出し、テキストから音声を生成する方法
- Read/Write Files from Diskノードでバイナリデータをディスクに保存する方法
- Execute Commandノードでffmpegを実行し、動画と音声を合成する方法
- 複数ノード間でバイナリデータを参照する方法({{ $('ノード名').first().binary.data }})
- 並列接続で複数の処理を同時に実行する方法
完成したワークフローの処理フロー
1. canva_Aシートからデータ取得
2. audio_statusが空の行をフィルタ
3. カテゴリフォルダ・アーカイブフォルダを検索(なければ作成)
4. 各投稿を1件ずつループ処理:
a. 動画ファイルを検索・ダウンロード
b. Fish Audio APIでnarration_1, narration_2を音声化
c. ffmpegで動画と音声を合成
d. 元動画をアーカイブフォルダに移動
e. 新動画を元のフォルダにアップロード
次のステップ
Module 02(後編)では、以下を実装します:
- ループ処理を完成させて全件処理
- audio_statusを「DONE」に更新
- 全カテゴリ(A〜E)への対応
参考資料
- Fish Audio API Documentation
- n8n HTTP Request Node
- n8n Read/Write Files from Disk
- n8n Execute Command Node
- FFmpeg Documentation
よくある質問
Q: なぜファイルをディスクに保存する必要があるのですか? A: ffmpegはディスク上のファイルを処理します。n8nのバイナリデータはメモリ上にあるため、ffmpegに渡すにはファイルとして保存する必要があります。また、大きなファイル(80MB以上)はメモリ制限に引っかかる可能性があるため、ディスクに保存する方が安定します。
Q: /tmpフォルダを使う理由は? A: /tmpは一時ファイル用のディレクトリで、n8nコンテナ内で書き込み権限があります。処理が終わればファイルは不要なので、一時ディレクトリが適切です。
Q: 音声を30秒ずつにする理由は? A: リール動画が約60秒で、前半と後半にナレーションを分けることで、視聴者の注意を維持しやすくなります。adelay=30000は30秒(30000ミリ秒)のオフセットを意味します。
Q: Wait 5sノードは必要ですか? A: Fish Audio APIのレート制限(無料: 100リクエスト/分)を考慮して追加しています。連続してAPIを呼び出すとエラーになる可能性があるため、間隔を空けています。
Q: 元動画をアーカイブする理由は? A: 音声合成済みの動画を同名でアップロードするため、元の動画を保持しておきたい場合にアーカイブが便利です。問題があった場合に元動画に戻せます。